[leetcode] #215 Kth Largest Element in an Array
下面的方法都太爛了,目標只有一個:如何 worst case = O(n)下實作 selection sort 。
其實就是透過 medians and order statistics 的概念。
Order Statistics 就是假設在一個 unsorted array 下要找到 i-th order 的值。要找到 maximum or minimum 一般可在 O(n) 下找到,即使是 i-th 也可以先作 O(nlogn) 的排序後找到。但是否有比 O(nlogn)更快的方法?
=> how can we modify quicksort to obtain expected-case $\theta(n)$
(hint) pivot, partition, but recur only on one set of data. no join
複習一下 divide and conquer (這裡叫做 randomized_select)
randomized_select 即便在一般時間是 O(n), worst case time complexity 仍是 O($n^{2}$)。
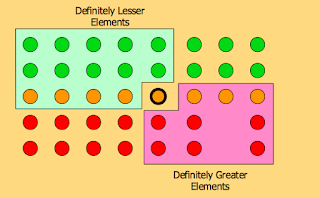
這裡用到一個 median of median (或者又稱為 quicksort median of 3/5) 的解法:
這讓 quicksort 在 sorting algorithm 又扳回一城了... lol
【參考】Stackoverflow How to find the kth largest element in an unsorted array of length n in O(n)?
題目要從一個無序的陣列中找到 K-th 大的值, 一開始想到的做法是:
1) 用一個 int[k] 陣列儲存k-th 大的值. 可是發現每次都得做 search/ O(log k), swap/ O(k), 這樣 worst case 會是 O(n*k).
2) 改進(1), 若 每掃一個 element v, 當 v < ref[0], 直接略過, 否則直接 ref[0] = v, 然後做 heapify / O(log k). worst case 變成 O(n*log k).
但其實這裡個 cost 需要增加 space O(k), 思考是否有 space O(1) and time O(n) 的解法:
=> insertion sort!!!
思考點:
step 1. 假設
a[0] =pivot,
idx_le = offset // values less and equal than pivot
idx_gt = end+1 // values greater than pivot
idx = offset;
step 2. 分堆
while (idx_le < idx_gt):
//partitioning
step3. 分完後, 理論上 [offset+1 - idx] ≤ pivot, [idx+1,end] > pviot
則我們會知道 pivot 是第 (end-idx)-th 大的值.
step4. 若 k = (end-idx)-th, pivot 則是答案, 否則往繼續往 [idx+1,end] 堆 或 [offset+1 - idx] (k' = k-(end-idx)).
這難度在於思考容易, 但是實作時 indexing 容易搞混... 需多注意.
其實就是透過 medians and order statistics 的概念。
Order Statistics 就是假設在一個 unsorted array 下要找到 i-th order 的值。要找到 maximum or minimum 一般可在 O(n) 下找到,即使是 i-th 也可以先作 O(nlogn) 的排序後找到。但是否有比 O(nlogn)更快的方法?
=> how can we modify quicksort to obtain expected-case $\theta(n)$
(hint) pivot, partition, but recur only on one set of data. no join
複習一下 divide and conquer (這裡叫做 randomized_select)
1: def RANDOMIZED_SELECT(A, p, r, i):
2: if p == r:
3: return p
4: q = PARTITION(A, p, r)
5: k = q-p+1
6: if k == i:
7: return A[:i+1]
8: elif k < i:
9: return RANDOMIZED_SELECT(A, q+1, r, i-k)
10: else:
11: return RANDOMIZED_SELECT(A, p, q-1, i)
12: def PARTITION(A, p, r):
13: pivot = A[r]
14: i = p - 1
15: for j in range(p, r):
16: if A[j] <= pivot:
17: j+=1
18: swap(A, i,j)
19: swap(i+1, r)
20: return i+1
randomized_select 即便在一般時間是 O(n), worst case time complexity 仍是 O($n^{2}$)。
這裡用到一個 median of median (或者又稱為 quicksort median of 3/5) 的解法:
1: divide n elements into groups of 5
2: find median of each group
3: use select(recursively to find median x of n/5 medians
4: partition the n elements around x.
5: let k = rank(x)
6: if i == k:
7: return x
8: elif i < k:
9: return select ( first_partition of i-th )
10: else:
11: return select ( last_partition of (i-k)-th )

這讓 quicksort 在 sorting algorithm 又扳回一城了... lol
【參考】Stackoverflow How to find the kth largest element in an unsorted array of length n in O(n)?
題目要從一個無序的陣列中找到 K-th 大的值, 一開始想到的做法是:
這難度在於思考容易, 但是實作時 indexing 容易搞混... 需多注意.

Comments
Post a Comment